Europe has the lowest employee engagement scores in the world.
Gallup’s State of the Global Workplace puts it at 13%. The UK sits at 10%. Portugal and Southern Europe trend lower still. Year after year – the same report, the same number, no improvement since at least 2016.
The standard response from the HR industry goes like this: European companies are bad at engagement. They need to invest more in culture. More listening sessions. More recognition programmes. More of whatever it is that American companies are apparently doing right.
There is a problem with this interpretation. The same Gallup datasets that produce the 13% number also show that European employees report lower stress than their American counterparts, higher wellbeing, less loneliness at work, and higher satisfaction with work-life balance. And European business performance – measured by productivity per hour worked, or by retention – is not consistently worse.
So either Europe has found a way to run healthy, productive companies with almost no engaged employees – or the model is measuring the wrong thing, in the wrong way, for this context.
I think it is the second.
The model doesn’t know where you are
The Gallup Q12 is the most widely used engagement instrument globally. Twelve questions, applied across 160 countries, producing the benchmark that most HR teams use to judge themselves.
It was developed and validated primarily in the United States.
One of the twelve items asks: "Do you have a best friend at work?" In the US, "best friend" is a casual phrase – you can have several. In the UK, it implies the single closest person in your entire life. In Portugal, melhor amigo carries a similar weight. The question means different things in different places. This is not a nuance. It is a structural problem with cross-cultural measurement.
More broadly: individualist cultures – the US, Australia, parts of Northern Europe – are more likely to self-report positively on items about personal performance and team relationships. They are also more willing to give high scores on Likert scales. More reserved or collectivist cultures – Portugal, France, Japan – systematically score lower, not because the underlying experience is worse, but because the response style is different.
This is well-documented in survey methodology research. It has a name: acquiescence bias, extreme response style, cultural response bias. It is not new. And HR analytics has largely ignored it.
The practical consequence: an HR team in Lisbon looking at their 11% engagement score against a 79% global benchmark is not seeing their organisation. They are seeing the artefact of a model calibrated elsewhere, applied here without adjustment.
How different can the results be? Perceptyx – using a different methodology on the same European workforce – reports engagement at 75.6%. Same population. Different instrument. The gap between 13% and 75.6% is not explained by reality. It is explained by how you ask the question.
The size problem compounds this
The measurement problem is not only cultural. It is structural.
Most people analytics benchmarks are built from large enterprise datasets. Insight222 reported in 2025 that the typical ratio is one people analytics practitioner per 2,500 employees. The companies that produce the data that feeds the benchmarks have 5,000, 10,000, 50,000 employees. Dedicated HR analytics functions. Mature HRIS systems. Years of clean data.
When a 300-person company in Porto tries to interpret their engagement data against those benchmarks, they are comparing structurally incomparable things. A company where the CEO knows everyone’s name operates by different organisational dynamics than a division of a multinational. A metric built for one cannot be read straightforwardly in the other.
This is not a complaint about access. It is a statement about statistical validity. Benchmarks built from a specific population do not generalise to a different population without recalibration. This is basic methodology. And yet, most platforms present these benchmarks as universal truth.
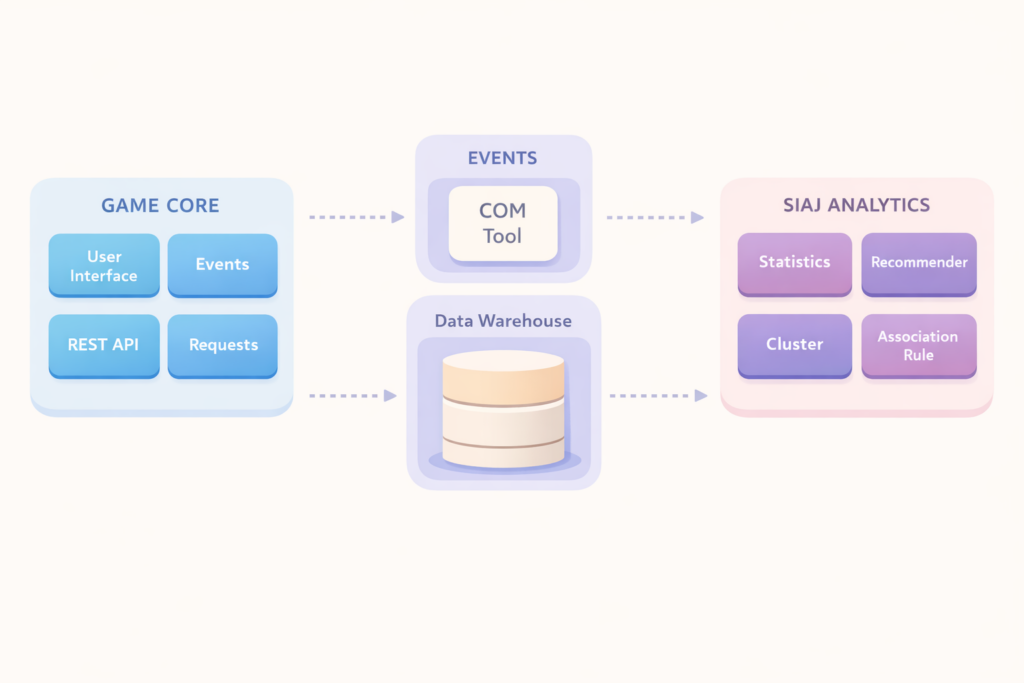
What this looks like when you’re building the systems
At GFoundry, we have spent ten years building and deploying engagement, performance, and talent systems for several companies. We have seen this problem from the inside – not as a research question, but as a deployment reality.
The research literature is full of examples where models built in one context produced misleading results in another.
Hanus and Fox (2015) ran a longitudinal study comparing gamified and non-gamified environments using leaderboards and badges. The gamified group showed decreased intrinsic motivation, lower satisfaction, and worse performance over time. The mechanism that was supposed to drive engagement actively undermined it – because the psychological relationship to competition and public recognition is not universal. It depends on context, culture, and how autonomy is perceived.
The cross-cultural survey research makes this even clearer. Kemmelmeier (2016) documents how response styles – acquiescence bias, extreme response style – vary systematically across cultures. North American and individualist cultures score higher on self-report scales not because the underlying experience is better, but because the response pattern is different. English-speaking countries consistently provide higher ratings compared to non-English-speaking Western European countries. This is not opinion. It is a well-documented measurement artefact.
And the consequences are real. Harvard Business Review has questioned the validity of the Q12 “best friend at work” item, noting that without a standard definition of what “best friend” indicates, answers are open to interpretation and give no quantifiable way to measure the health of company culture. When that single item contributes to a composite score used to benchmark 160 countries against each other, the measurement problem is not academic. It is operational.
In each case, the model was not broken. It was just not built for every context where it was being used.
Three questions before you trust the output
Here is the framework we use internally – and the one I would recommend to any European company deploying people analytics.
1. Where was this model trained?
Every engagement benchmark, attrition predictor, or skills framework carries the imprint of the data it was built on. If the training data is predominantly large US enterprise, the model’s internal logic reflects that context. Ask the vendor: what was the sample composition? What is the average company size, geography, and sector of the benchmark? If they cannot answer this – or if the answer is "it’s proprietary" – be cautious about any comparison they ask you to make.
2. What is the model actually measuring – and is that the same thing in your context?
A score is not a fact. It is a measurement of something, using a particular instrument, in a particular language, interpreted through a particular cultural lens. Before drawing conclusions, ask: does this instrument behave consistently across the cultural and organisational contexts present in our company? Has anyone validated that a high score means the same thing here as it does in the benchmark population?
3. What decision would change if this number were different?
This is the most important question, and the one most people analytics implementations skip. If the answer is "nothing" – if the score exists for reporting purposes but does not change what managers do, who gets developed, how headcount is planned – then the cost of a miscalibrated model is low. If real decisions flow from this number, the cost of ignoring its context-dependency is high.
What to do about it
For a company deploying people analytics in Europe – especially an SME:
Understand the benchmark before you benchmark against it. Ask where the comparison data comes from. A benchmark built from 500 Fortune 500 US companies is not a valid reference for a 250-person company in Lisbon. It is not even a valid reference for a 250-person company in Chicago. Size matters as much as geography.
Build internal benchmarks first. For most European SMEs, the most meaningful comparison is to themselves over time. Trend data within the company – are we improving quarter over quarter on the dimensions we care about? – is more actionable than a cross-company benchmark built from a population that does not resemble you.
Disaggregate before comparing. If you have teams in different countries, cities, or with meaningfully different working arrangements, do not compare them on the same scale without adjusting for context. A remote team in rural Portugal and an office team in Lisbon are not the same population for engagement purposes.
Validate locally before scaling. A recognition programme that worked in a UK subsidiary is not guaranteed to work in a Spanish one. A feedback cadence that feels right in a fast-moving tech team may feel intrusive in a more traditional industrial context. Pilot before assuming.
What we don’t know
This matters – and I want to be explicit about it.
We do not have a clean answer to the central problem. The honest position is: we do not yet know how to build truly context-aware people analytics models at scale. The tooling does not exist in a mature form. Most platforms offer regional filters, not regional model recalibration. Filtering data by country is not the same as building a model that accounts for how response patterns, cultural norms, and labour market structures differ across countries.
We also do not know how much of the European low-engagement pattern is measurement artefact and how much is genuine structural difference. Some of it is surely real – European labour markets, regulatory protections, and cultural attitudes toward work are genuinely different from American ones, and that will show up in how people relate to their organisations. Academic work on welfare state structures and work engagement shows that the institutional framework around work, not just company practices, explains variation across Europe.
Separating signal from noise here is a real, unsolved research problem. Anyone who tells you they have solved it is selling something.
The first step
The first step is not better models. The first step is honesty about the models we have.
A metric that produces systematically implausible results across an entire continent is not revealing a problem. It is the problem. Reading a 13% engagement score as organisational failure – when the same employees report higher wellbeing, lower stress, and comparable productivity – is not data-driven decision making. It is model-driven confusion.
The benchmark was built elsewhere. It does not know where you are. Start there.